





HSLVision is a whIRLwind project. Our mission is to push the boundaries of robotics and AI in robot football. We are always looking for interested students or collaboration partners to join us. Learn more at whirlwind.team.
Images in HSLVision were collected across six locations: LAB42 (whIRLwind), German Open 2026 Cologne (whIRLwind), RCAP Beijing Masters 2025 (whIRLwind, HTWK), RoboCup 2025 Salvador (HTWK), RoboCup 2019 Sydney (BitBots), and RoboCup 2017 Nagoya (BitBots). It spans a range of field layouts, goalpost designs, ball sizes, and robot platforms - the Booster Robotics K1 and T1, as well as several non-standard KidSize humanoids - recorded across the small, middle, and large HSL field sizes. An additional 770 annotated images from RCAP Abu Dhabi 2025 are held out to evaluate performance on unseen venues.






One annotated frame per recording location, with ground-truth boxes drawn in the class palette.
Raw footage is subsampled at 3 fps and filtered to remove motion blur, occlusion, and low-quality frames. To avoid near-identical, redundant images, we embed each frame with a pretrained DINOv3 ViT-S/16 encoder (384-dimensional pooler token, L2-normalized so cosine similarity reflects distance) and iteratively remove the image with the most above-threshold neighbors until no pair exceeds a similarity threshold τ. This yields a diverse subset without depending on frame order, while a pretrained encoder avoids per-dataset training and provides a semantically meaningful embedding.
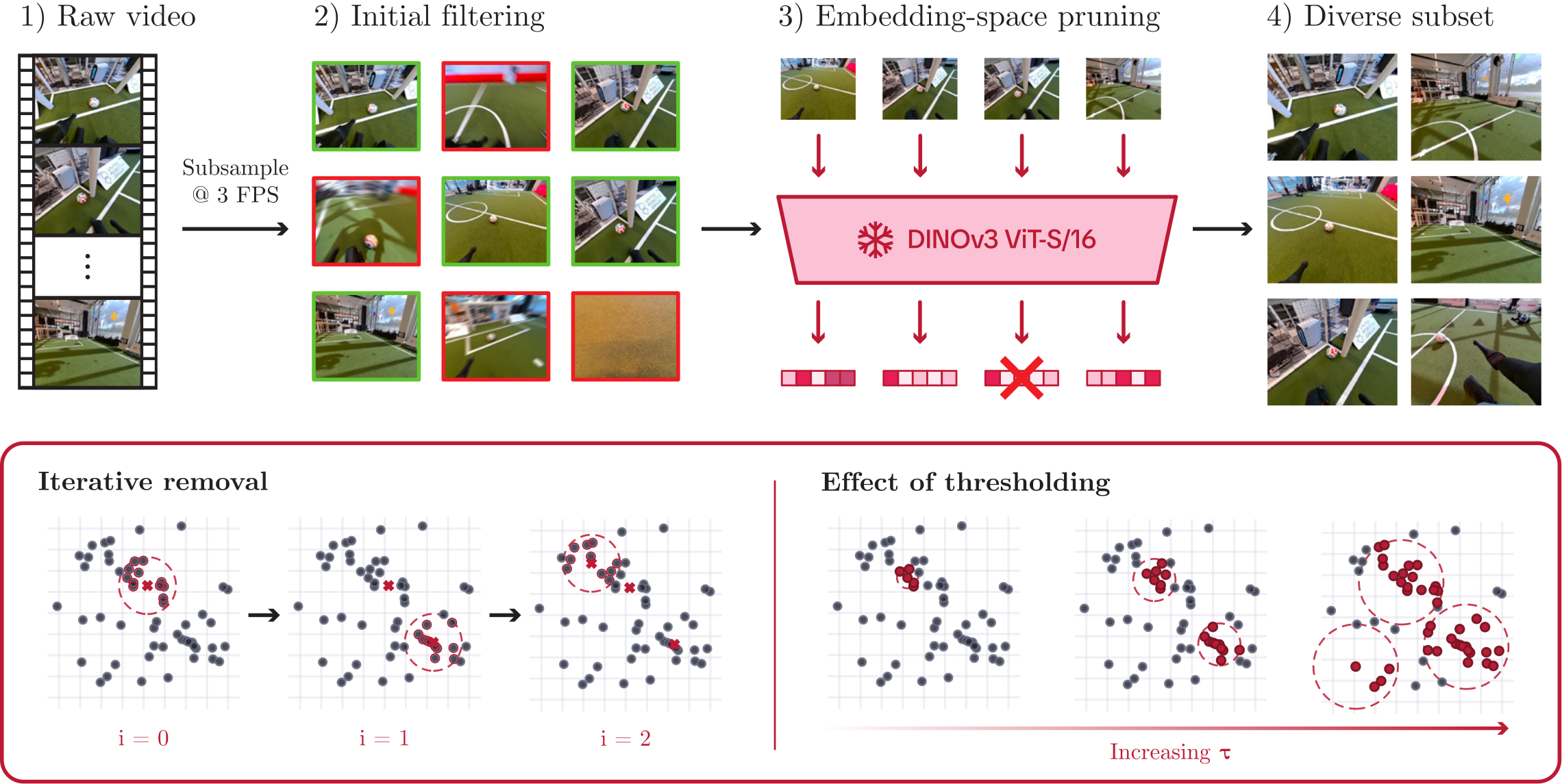
Figure 1. Overview of the data-selection pipeline. Bottom: embedding-space pruning iteratively removes points with many nearby neighbors, and the effect of varying τ on the diversity of the selected subset.
Onboard stereo depth is not available across all recording platforms, so every color frame is instead paired with a depth map estimated using DepthAnythingV3, which predicts per-pixel metric depth from a single RGB image. The depth maps are aligned with the RGB images and share the same pixel coordinates, so annotations apply directly to both modalities without any transformation.

Figure 2. RGB input, Hobot StereoNet, and DepthAnythingV3 predictions across two scenes. DepthAnythingV3 produces smoother, more spatially consistent depth with sharp, well-localized object boundaries.
HSLVision is released under a CC BY 4.0 license and available on Hugging Face. The release includes annotations, RGB images, and depth maps, divided into train / validation / test splits. All code for model evaluation, dataset tooling, and depth-map generation will be released publicly on GitHub upon acceptance.
@inproceedings{catarrinho2026hslvision,
author = {Xavier Catarrinho, D. M. and de Jong, G. and Meijer, M. J. and Ruiter, H. and Honkoop, M.},
title = {HSLVision: A Multimodal Vision Dataset for RoboCup Humanoid Soccer},
booktitle = {RoboCup 2026: Robot World Cup XXIX},
year = {2026},
location = {Incheon, South Korea},
}HSLVision is a whIRLwind project. Our mission is to push the boundaries of robotics and AI in robot football. We are always looking for interested students or collaboration partners to join us. Learn more at whirlwind.team.